The Rise of Audio in AI
This is an exploration of how audio is represented in ML/AI models. I am sharing my understanding of how models understand audio, told through the history of notable breakthroughs in the field.
It's always a good idea to start from the ground up. What is audio? This is an example soundwave:

We have an audio signal and a receiver (a microphone). The receiver captures the analog voltage and digitizes it into samples many times a second - for example 44100 times (44.1 kHz) for CD-quality audio. Put simply, the microphone has a sensitive diaphragm that reacts to changes in air pressure. A snapshot of the diaphragm's position is taken at high frequency. Better mics are more accurate and have a better dynamic range, but the core principle remains. And if we were to plot all the recorded values, we get a reconstruction like the soundwave above.
So, audio files are already just vectors of numbers, which makes them seem ready for modeling. However, audio has properties that can be utilized to lessen the curse of dimensionality. For example, there's no need to equally represent every sound that a mic can pick up - it makes sense to focus on the ranges perceived by the human ear, and especially human speech.
Below is a typical soundwave of the English alphabet. Note that different accents will naturally look different:

To model English, the goal is to learn how to differentiate between the soundwaves above. It's trickier than simply recognizing a pattern - there are accents, background noise, multiple speakers... In practice, audio is often a bunch of soundwaves overlaid on top of each other and a good ML model should be able to disentangle them.
Before walking through the history of modelling audio, let's clarify a few related terms: vector: in this context, the raw audio signal embedding: a transformed, learnt mathematical representation of a "bit" of audio token: an ID resulting from a mapping quantization: a "lossy" mapping used when the signal space is too large. Rather than letting the token vocabulary explode, so we round values to a managaeble set of IDs codeword: the mapped bit of audio, after quantization codebook: dictionary of all possible mappings
1. wav2vec (2019, Meta/Facebook) A notable breakthrough was wav2vec which directly processed the raw vector. In simple terms, a neural net was trained on a large corpus of recorded speech to predict future values in the signal. The model learned via "contrastive loss" - the goal is to choose the actual next value over sampled distractor values.
The original wav2vec was somewhat difficult to use - it's purely an encoder and requires an additional model to generate output (like transcription). Moreover, using raw audio vectors is wasteful because the space is huge and sparse. It's more meaningful to teach the model to differentiate between "bin" and "pin" than between "bin" and an airplane flying past.
2. wav2vec 2.0 (2020, Meta/Facebook) Arrived with a modernized architecture - a mix of convolution and transformer. It no longer predicts a future value, but rather masks and tries to guess parts of the sequence - similar to how BERT handles text.
The more interesting breakthrough is the quantization of audio. Audio is a much richer signal than text, so the we can't simply constrain our vocabulary using something like BPE, the way text-LLMs are doing. Instead wav2vec 2.0 learns a lossy tokenization method from the training data. However, backpropagation isn't applicable to discrete tokens, so the Gumbel-softmax trick is employed. A random number is pulled from Gumbel distribution and is added to the input, followed by softmax. This makes the math differentiable and the model can explore different codewords.
3. Whisper (2022, OpenAI) It's remarkable how widely Whisper is used even today, in 2026. Still an industry standard, its longevity is a testament to how powerful it is.
The preprocessing step was completely revamped. Instead of struggling with raw audio values, Whisper simplifies the input space by using log-Mel spectograms, turning audio into an image.
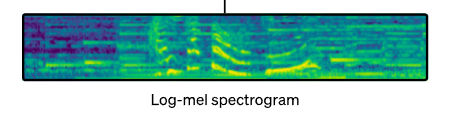
The x-axis is time and the y-axis is frequency, in log-Mel scale. The pixel intensity is the amplitude at that frequency-time point. Sound has the inherent property to repeat, and Fourier Transform can extract these frequencies. The mel scale is a model of how the human ear hears frequencies; more space on the diagram is attributed to the human-speech frequencies.
We transformed 2d array containing time and intensity to 3d - time, intensity and frequency. We didn't add anything new - we just rearranged the original vector, a.k.a feature engineering. A sliding window of such spectograms is the input to Whisper. With the added benefit of unprecedented scale and variety of audio used and transformer encoder-decoder architecture - the results were groundbreaking at the time.

In the post-Whisper period, the "winner" architecture is still an open game. As great as Whisper is, it's not perfect - it makes mistakes and struggles with background noise and has an inherent delay because audio is processed in chunks.
Current LLMs are expanding beyond text and increasingly understand audio. This is usually done by plugging in an audio encoder directly into the LLM, expanding its token vocabulary beyond just text (and images). While this works for speech understanding, capturing nuances such as tone, speaker identification or background noise is trickier to solve since there is no direct mapping to text.
Notable Mention: Moshi (Kyutai, 2024) Moshi represents a shift toward true "streaming" audio. They use an audio codec (encoder-decoder) called Mimi for both input and output. Mimi handles both "semantic" (word meaning) and "acoustic" tokens (the sound texture).
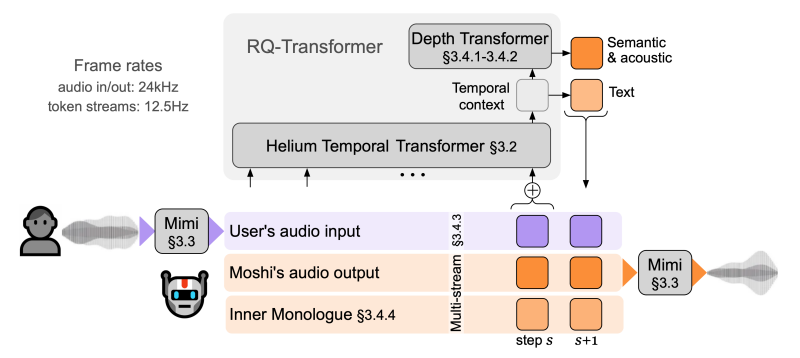
Unlike traditional LLMs that wait for a sequence to finish before reading input, Moshi's LLM streams both thought and input tokens simultaneously, allowing real-time interruptions. They use Residual Vector Quantization (RVQ) - stacking multiple layers of quantization. Each subsequent layer minimizes the quantization loss of the previous. This codec scheme is widely used in practice for other models.
Audio remains unsolved. We have come a long way; speech-to-text and text-to-speech are now taken for granted. However, there is still a gap when modeling audio without involving text. So far audio feels like an afterthought and perhaps it is time for more audio-first models.